linuxPIPEpower 2w ago • 100%
someone else can probably give a more comprehensive/correct answer but here is how I understand it. i believe chromium is open source and chrome is mostly chromium but also some proprietary (and therefor unknown) bits are included. whereas firefox is entirely open source, meaning you could compile it yourself and still end up with the same package.
linuxPIPEpower 3mo ago • 100%
For nonidentical devices you create additional packages prefixed with specific device name. You don’t need to link all packages at once with stow, pass a name of a package to link it alone.uuu
Sooo... I find some way to share the dotfiles directory across devices (rsync, syncthing, git, nextcloud, DAV) then make specific subdirs like this?:
~
- dotfiles
- bash-desktop
dot-bashrc
dot-bash_profile
- bash-laptop
dot-bashrc
dot-profile
dot-bash_profile
But what is the software doing for me? I'm manually moving all these files and putting them together in the specific way requested. Setting the whole thing up is most of the work. Anyone who can write a script to create the structure can just as easily write it to make symlinks. I'm sure I'm missing something here.
linuxPIPEpower 3mo ago • 100%
yadm is the one I liked the best and tried it a few times. fact is that I am unlikely to keep a repo like this even part way up to date. New files are created all the time and not added, old ones don't get updated or removed. There's not even a good way to notice in any file manager what is included and what's not as far as I know. yadm doesn't work with tools like eza which can display the git status of files in repos. (and it probably wouldn't be feasible.)
Plus I have some specific config collections already in change tracking and it makes more sense to keep it that way. Having so many unrelated files together in one project is too chaotic and distracting.
It's not realistic for me to manage merges, modules, cherry picking, branches all that for so many files that change constantly without direct intervention. Quickly enough git will tie itself into some knot and I won't be able to pick it apart.
Once again I try to get a handle of my various dotfiles and configs. This time I take another stab at `gnu stow` as it is often recommended. I do not understand it. Here's how I understand it: I'm supposed to manually move all my files into a new directory where the original are. So for `~` I make like this: ``` ~ - dotfiles - bash dot-bashrc dot-bash_profile - xdg - dot-config user-dirs.dirs - tealdeer - dot-config - tealdeer config.toml ``` then `cd ~/dotfiles && stow --dotfiles .` Then (if I very carefully created each directory tree) it will symlink those files back to where they came from like this: ``` ~ .bashrc .bash_profile - .config user-dirs.dirs - tealdeer config.toml ``` I don't really understand what this application is *doing* because setting up the `dotfiles` directory is a lot more work than making symlinks afterwards. Every instructions tells me to make up this directory structure by hand but that seems to tedious with *so many* configs; isn't there some kind of automation to it? Once the symlinks are created then what? - Tutorials don't really mention it but the actual manual gives me the impression this is a packager manager in some way and that's confusing. Lots of stuff about compiling - I see about how to combine it with `git`. Tried `git`-oriented dotfile systems before and they just aren't practical for me. And again I don't see what `stow` contributing; `git` would be doing all the work there. - Is there anything here about sharing configs between non-identical devices? Not everything can be copy/pasted exactly. Are you supposed to be making `git` branches or something? The [manual](https://www.gnu.org/software/stow/manual/stow.html) is not gentle enough to learn from scratch. OTOH there are very very short tutorials which offer little information. I feel that I'm really missing the magic that's obvious to everyone else.
linuxPIPEpower 3mo ago • 100%
Ya you're right I am thinking "partial upgrade"; I just thought the concept might generalize.
I guess the worst that could happen with a partial install would be some deps installed in the system but then not actually required.
Some packages install in under a minute, while alternatives which seem functionally similar, take *hours*. Sometimes there are several available options to fit a use case and I would like to use it *now*. Is it possible to anticipate which one will *likely* be the fastest to get rolling? Generally I like to install via `yay`. Searching around here is what I learned. Agree?: - AUR will be slower - Certain categories of package, like web browser, are inherently slow - Selecting `-bin` will be faster if available Is there some way to guess beyond that? Certain programing languages take longer than others? Is it in relationship to existing packages on the system? Other characteristic? Some kind of dry-run feature to estimate? Obviously I don't have the fastest computer. I have added `MAKEFLAGS="-j4"` to `/etc/makepkg.conf` so at least all 4 cores can get used. Once I realize a package is going to take ages to get ready, is it possible to safely intervene to stop the process? I try to avoid it because in general I understand arch-based distros don't like "partial" installs. But is it safe to stop compiling? No changes have yet been made, right?
linuxPIPEpower 5mo ago • 100%
I used to use floccus and the thing I really liked is you can selectively share bookmark groups. So if you have certain links you want everywhere you can do that, but some sets you might only want in in specific browsers. I do not know if the others that have this.
Stopped using it because of unresolvable problems and not much Dev attention but looks like its picked up again so I plan to get back to it.
linuxPIPEpower 5mo ago • 100%
I agree. Chromebooks are a viable choice for those who want a web terminal. I used one for about a year. Got the job done.
linuxPIPEpower 5mo ago • 100%
thanks for all the details! I've fairly recently done an FS migration that entailed moving all data, reformatting, and moving it all back. Mega pain in the ass. I know more now than I did at the start of that project, so wouldn't be as bad but not getting into something like that lightly.
Though it might be the excuse I need to buy another 12 tb hdd...
linuxPIPEpower 5mo ago • 100%
TBD
I've been struggling with syncthing for a few weeks... It runs super hot on every device. Need to figure out how to chill it out a bit.
Other than that I'll look at both NFS and WebDAV some more. Then will come back to this page to re read the more intricate suggestions.
linuxPIPEpower 5mo ago • 100%
thanks I appreciate it. I've been around the block enough times to expect maximalist advice in places like this. people who are motivated to be hanging around in a forum just waiting for someone to ask a question about hard drives are coming from a certain perspective. Honestly, it's not my perspective. But the information is helpful in totality even though I'm unlikely to end up doing what any one person suggests.
RAID is something I've seen mentioned over and over again. Every year or two I go reading about them more intentionally and never get the impression it's for me. Too elaborate to solve problems I don't have.
linuxPIPEpower 5mo ago • 100%
Thanks this comment is v helpful. A persuasive argument for NFS and against sshfs!
linuxPIPEpower 5mo ago • 50%
Forget NFS, SSHFS and syncthing as those are to complex and overkill at the moment. SMB is dead simple in a lot of ways and is hard to mess up.
OTOH, SSHFS and syncthing are already humming along and I'm framiliar with them. Is SMB so easy or having other benefits that would make it better even though I have to start from scratch? It looks like it (and/or NFS) can be administered from cockpit web interface which is cool.
Now that I look around I think I actually have a bit of RAM I could put in the PC. MacMini's original RAM which is DDR3L; but I read you can put it in a device that wants DDR3. So I will do that next time it's powered off.
Thanks for letting me know I could use an expansion card. I was wondering about that but the service manual didn't mention it at all and I had a hard time finding information online.
Is this the sort of thing I am looking for: SATA Card 4 Port with 4 SATA Cables, 6 Gbps SATA 3.0 Controller PCI Express Expression Card with Low Profile Bracket Support 4 SATA 3.0 Devices ($23 USD) I don't find anything cheaper than that. But there are various higher price points. Assuming none of those would be worthwhile on a crummy old computer like I have. Is there any specific RAID support I should look for?
I have only the most cursory knowledge of RAID but can tell it becomes important at some point.
But am I correct in my understanding that putting storage device in RAID decreases the total capacity? For example if I have 2x6TB in RAID, I have 6 TB of storage right?
Honestly, more than half my data is stuff I don't care too much about keeping. If I lose all the TV shows I don't cry over it. Only some of it is stuff I would care enough to buy extra hardware to back up. Those tend to be the smaller files (like documents) whereas the items taking up a lot of space (media files) are more disposable. For these ones "good enough" is "good enough".
I really appreciate your time already and anything further. But I am still wondering, to what extent is all this helping me solve my original question which is that I want to be able to edit remote files on Desktop as easily as if they were local on Laptop? Assuming i got it all configured correctly, is GIMP going to be just as happy with a giant file lots of layers, undos, etc, on the Desktop as it would be with the same file on Laptop?
linuxPIPEpower 5mo ago • 100%
Do you mean take the board out of this case and put it in another, bigger one?
I actually do have a larger, older tower that I fished out of the trash. Came with a 56k modem! But I don't know if they would fit together. I also don't notice anywhere particularly suitable to holding a bunch of storage; I guess I would have to buy (or make?) some pieces.
Here is the board configuration for the Small Form Factor:
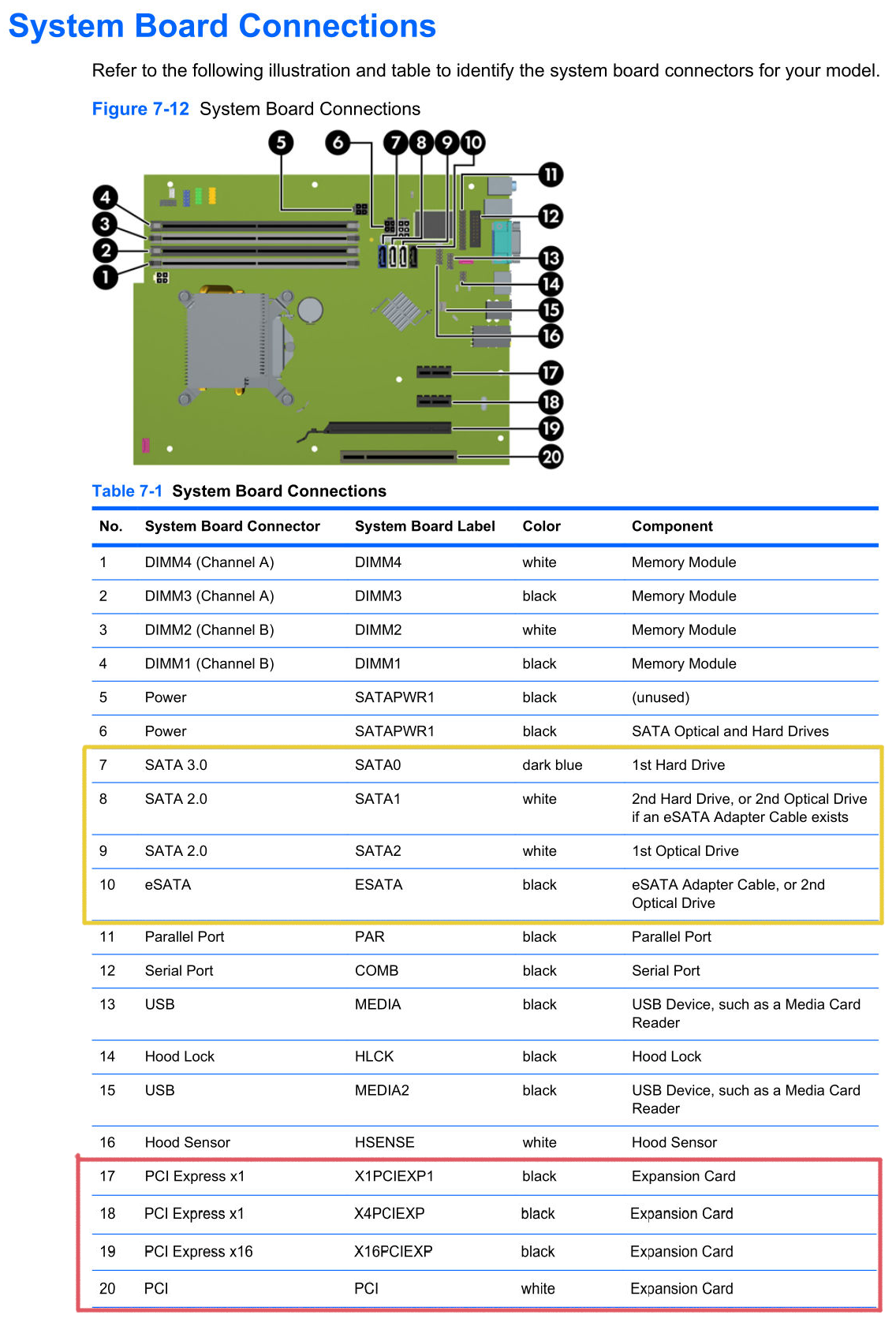
I did try using #9 and #10 for storage and I seem to recall it kind of worked but didn't totally work but not sure of the details. But hey, at least I can use a CD drive and a floppy drive at the same time!
linuxPIPEpower 5mo ago • 100%
Thanks! I have gone to look at TrueNAS or FreeNAS a few times over the years. I am dissuaded because hardware-wise they seem expensive. Then on the other hand, they are limited in what they can do.
Comprehension check. Is the below accurate?
- TrueNAS is an OS, it would replace Debian.
- Main purpose of TrueNAS is to maintain the filesystem
- There are some packages available for TrueNAS, like someone mentioned Syncthing supports it
- But basically if I run TrueNAS, I will likely need a second computer to run services
Also for comprehension check:
- The reason many people are recommending NAS (or WebDAV, NFS, VPN etc) is because with better storage and network infrastructure I would no longer be interested in this caching idea.
- Better would be to have solid enough file sharing within the LAN that accessing files located on Desktop from Laptop would work.
- The above would be completely plausible
How'm I doing?
linuxPIPEpower 5mo ago • 100%
sounds sweet! Perfectly what I am looking for.
It's so rare to be jealous of windows users!!
I do find this repo: jstaf/onedriver: A native Linux filesystem for Microsoft OneDrive. So I guess in theory it would be possible in linux? If you could apply it to a different back end..
linuxPIPEpower 5mo ago • 100%
Thanks!
I elaborated on why I'm using USB HDDs in this comment. I have been a bit stuck knowing how to proceed to avoid these problems. I am willing to get a new desktop at some point but not sure what is needed and don't have unlimited resources. If I buy a new device, I'll have to live with it for a long time. I have about 6 or 8 external HDDs in total. Will probably eventually consolidate the smaller ones into a larger drive which would bring it down. Several are 2-4TB, could replace with 1x 12TB. But I will probably keep using the existing ones for backup if at all possible.
Re the VPN, people keep mentioning this. I am not understanding what it would do though? I mostly need to access my files from within the LAN. Certainly not enough to justify the security risk of a dummy like me running a public service. I'd rather just copy files to an encrypted disk for those occasions and feel safe with my ports closed to outsiders.
Is there some reason to consider a VPN for inside the LAN?
linuxPIPEpower 5mo ago • 100%
-
In another comment I ran iperf3 Laptop (wifi) ---> Desktop (ethernet) which was about 80-90MBits/s. Whereas Desktop ---> OtherDesktop was in the 900-950 MBits/s range. So I think I can say the networking is fine enough when it's all ethernet. Is there some other kind of benchmarking to do?
-
Just posted a more detailed description of the desktops in this comment (4th paragraph). It's not ideal but for now its what I have. I did actually take the time (
gnome-disksbenchmarking) to test different cables, ports, etc to find the best possible configuration. While there is an upper limit, if you are forced to use USB, this makes a big difference. -
Other people suggested ZeroTier or VPNs generally. I don't really understand the role this component would be playing? I have a LAN and I really only want local access. Why the VPN?
-
Ya, I have tried using syncthing for this before and it involves deleting stuff all the time then re-syncing it when you need it again. And you need to be careful not to accidentally delete while synced, which could destroy all files.
-
Resilio I used it a long time ago. Didn't realize it was still around! IIRC it was somewhat based on bittorrent with the idea of peers providing data to one another.
linuxPIPEpower 5mo ago • 75%
Maybe Syncthing is the way forward. I use it for years and am reasonably comfortable with it. When it works, it works. Problems is that when it doesn't work, it's hard to solve or even to know about. For the present use case it would involve making a lot of shares and manually toggling them on and off all the time. And would need to have some kind of error checking system also to avoid deleting unsynced files.
Others have also suggested NFS but I am having a difficult time finding basic info about what it is and what I can expect. How is it different than using SSHFS mounted? Assuming I continue limping along on my existing hardware, do you think it can do any of the local caching type stuff I was hoping for?
Re the hardware, thanks for the feedback! I am only recently learning about this side of computing. Am not a gamer and usually have had laptops, so never got too much into the hardware.
I have actually 2 desktops, both 10+ years old. 1 is a macmini so there is no chance of getting the storage properly installed. I believe the CPU is better and it has more RAM because it was upgraded when it was my main machine. The other is a "small" tower (about 14") picked up cheaply to learn about PCs. Has not been upgraded at all other than SSD for the system drive. Both running debian now.
In another comment I ran iperf3 Laptop (wifi) ---> Desktop (ethernet) which was about 80-90MBits/s. Whereas Desktop ---> OtherDesktop was in the 900-950 MBits/s range. So I think I can say the networking is fine enough when it's all ethernet.
One thing I wasn't expecting from the tower is that it only supports 2x internal HDDs. I was hoping to get all the loose USB devices inside the box, like you suggest. It didn't occur to me that I could only get the system drive + one extra. I don't know if that's common? Or if there is some way to expand the capacity? There isn't too much room inside the box but if there was a way to add trays, most of them could fit inside with a bit of air between them.
This is the kind of pitfall I wanted to learn about when I bought this machine so I guess it's doing its job. :)
Efforts to research what I would like to have instead have led me to be quite overwhelmed. I find a lot of people online who have way more time and resources to devote than I do, who want really high performance. I always just want "good enough". If I followed the advice I found online I would end up with a PC costing more than everything else I own in the world put together.
As far as I can tell, the solution for the miniPC type device is to buy an external drive holder rack. Do you agree? They are sooo expensive though, like $200-300 for basically a box. I don't understand why they cost so much.
linuxPIPEpower 5mo ago • 100%
What would be the role of Zerotier? It seems like some sort of VPN-type application. I don't understand what it's needed for though. Someone else also suggested it albeit in a different configuration.
Just doing some reading on NFS, it certainly seems promising. Naturally ArchWiki has a fairly clear instruction document. But I am having a ahrd time seeing what it is exactly? Why is it faster than SSHFS?
Using the Cache with NFS > Cache Limitations with NFS:
Opening a file from a shared file system for direct I/O automatically bypasses the cache. This is because this type of access must be direct to the server.
Which raises the question what is "direct I/O" and is it something I use? This page calls direct I/O "an alternative caching policy" and the limited amount I can understand elsewhere leads me to infer I don't need to worry about this. Does anyone know otherwise?
The issue with syncing, is usually needing to sync everything.
yes this is why syncthing proved difficult when I last tried it for this purpose.
Beyond the actual files ti would be really handy if some lower-level stuff could be cache/synced between devices. Like thumbnails and other metadata. To my mind, remotely perusing Desktop filesystem from Laptop should be just as fast as looking through local files. I wouldn't mind having a reasonable chunk of local storage dedicated to keeping this available.
linuxPIPEpower 5mo ago • 100%
What would be the role of Zerotier? It seems like some sort of VPN-type application. What do I need that for?
rclone is cool and I used it before. I was never able to get it to work really consistently so always gave up. But that's probably use error.
That said, I can mount network drives and access them from within the file system. I think GVFS is doing the lifting for that. There are a couple different ways I've tried including with rclone, none seemed superior performance-wise. I should say the Desktop computer is just old and slow; there is only so much improvement possible if the files reside there. I would much prefer to work on my Laptop directly and move them back to Desktop for safe keeping when done.
"vfs cache" is certainly an intriguing term
Looks like maybe the main documentation is rclone mount > vfs-file-caching and specifically --vfs-cache-mode-full
In this mode the files in the cache will be sparse files and rclone will keep track of which bits of the files it has downloaded.
So if an application only reads the starts of each file, then rclone will only buffer the start of the file. These files will appear to be their full size in the cache, but they will be sparse files with only the data that has been downloaded present in them.
I'm not totally sure what this would be doing, if it is exactly what I want, or close enough? I am remembering now one reason I didn't stick with rclone which is I find the documentation difficult to understand. This is a really useful lead though.
linuxPIPEpower 5mo ago • 100%
I don't know what that means
Title is TLDR. More info about what I'm trying to do below. My daily driver computer is **Laptop** with an SSD. No possibility to expand. So for storage of lots n lots of files, I have an old, low resource **Desktop** with a bunch of HDDs plugged in (mostly via USB). I can access **Desktop** files via SSH/SFTP on the LAN. But it can be quite slow. And sometimes (not too often; this isn't a main requirement) I take **Laptop** to use elsewhere. I do not plan to make **Desktop** available outside the network so I need to have a copy of required files on **Laptop**. Therefor, sometimes I like to move the remote files from **Desktop** to **Laptop** to work on them. To make a sort of local cache. This could be individual files or directory trees. But then I have a mess of duplication. Sometimes I forget to put the files back. Seems like **Laptop** could be a lot more clever than I am and help with this. Like could it *always* fetch a remote file which is being edited and save it locally? Is there any way to have **Laptop** fetch files, information about file trees, etc, located on **Desktop** when needed and smartly put them back after editing? Or even keep some stuff around. Like lists of files, attributes, thumbnails etc. Even browsing the directory tree on **Desktop** can be slow sometimes. I am not sure what this would be called. Ideas and tools I am already comfortable with: - rsync is the most obvious foundation to work from but I am not sure exactly what would be the best configuration and how to manage it. - [luckybackup](https://luckybackup.sourceforge.net/) is my favorite rsync GUI front end; it lets you save profiles, jobs etc which is sweet - [freeFileSync](https://freefilesync.org/) is another GUI front end I've used but I am preferring lucky/rsync these days - I don't think git is a viable solution here because there are already git directories included, there are many non-text files, and some of the directory trees are so large that they would cause git to choke looking at all the files. - [syncthing](https://syncthing.net/) might work. I've been having issues with it lately but I may have gotten these ironed out. Something a little more transparent than the above would be cool but I am not sure if that exists? Any help appreciated even just idea on what to web search for because I am stumped even on that.
For a given device, sometimes one linux distro perfectly supports a hardware component. Then if I switch distros, the same component no longer functions at all, or is very buggy. How do I find out what the difference is?
Does anyone else find javascript/electron-based code editors confusing? I can never understand the organization/hierarchies of menus, buttons, windows, tabs. All my time is spent hunting through the interface. My kingdom for a normal dialogue box! I've tried and failed to use VSCodium on a bunch of occasions for this reason. And a couple other ones. It's like the UI got left in the InstaPot waaaay too long and now it's just a soggy stewy mess. Today I finally thought I'd take the first step toward android development. Completing a very simple [hello world](https://developer.android.com/codelabs/basic-android-kotlin-compose-first-app) tutorial is proving to be challenging just because the window I see doesn't precisely correspond to the screenshots. Trying to find the buttons/menus/tools is very slow as I am constantly getting lost. I only ever have this in applications with javascript-based UIs Questions: 1. Am I the only one who faces this challenge? 2. Do I have to use Android Studio or it there some kind of native linux alternative? edited to reflect correction that Android Studio is not electron
cross-posted from: https://discuss.tchncs.de/post/13814482 > I just noticed that [`eza`](https://github.com/eza-community/eza) can now display total disk space used by directories! > > I think this is pretty cool. I wanted it for a long time. > > There are other ways to get the information of course. But having it integrated with all the other options for listing directories is fab. `eza` has features like `--git`-awareness, `--tree` display, clickable `--hyperlink`, filetype `--icons` and other display, permissions, dates, ownerships, and other stuff. being able to mash everything together in any arbitrary way which is useful is handy. And of course you can `--sort=size` > > [docs](https://github.com/eza-community/eza/blob/main/man/eza.1.md): > > ``` > --total-size show the size of a directory as the size of all > files and directories inside (unix only) > ``` > > It also (optionally) color codes the information. Values measures in kb, mb, and gb are clear. Here is a screenshot to show that: > > ```sh > eza --long -h --total-size --sort=oldest --no-permissions --no-user > ``` > > > 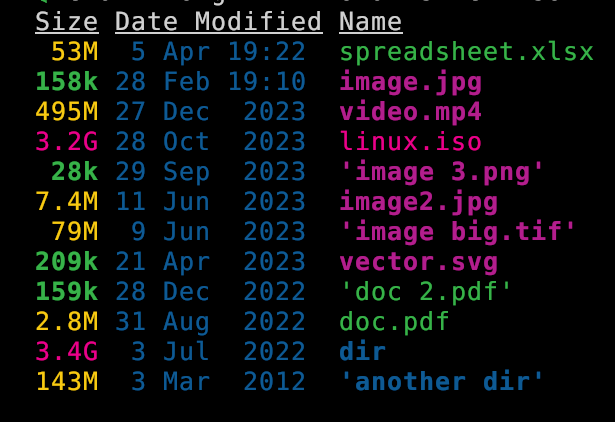 > > Of course it take a little while to load large directories so you will not want to use by default. > > Looks like it was first implemented Oct 2023 with some fixes since then. ([Changelog](https://github.com/eza-community/eza/blob/main/CHANGELOG.md)). [PR #533 - feat: added recursive directory parser with \`--total-size\` flag by Xemptuous](https://github.com/eza-community/eza/pull/533) > > > > > >
I just noticed that [`eza`](https://github.com/eza-community/eza) can now display total disk space used by directories! I think this is pretty cool. I wanted it for a long time. There are other ways to get the information of course. But having it integrated with all the other options for listing directories is fab. `eza` has features like `--git`-awareness, `--tree` display, clickable `--hyperlink`, filetype `--icons` and other display, permissions, dates, ownerships, and other stuff. being able to mash everything together in any arbitrary way which is useful is handy. And of course you can `--sort=size` [docs](https://github.com/eza-community/eza/blob/main/man/eza.1.md): ``` --total-size show the size of a directory as the size of all files and directories inside (unix only) ``` It also (optionally) color codes the information. Values measures in kb, mb, and gb are clear. Here is a screenshot to show that: ```sh eza --long -h --total-size --sort=oldest --no-permissions --no-user ``` 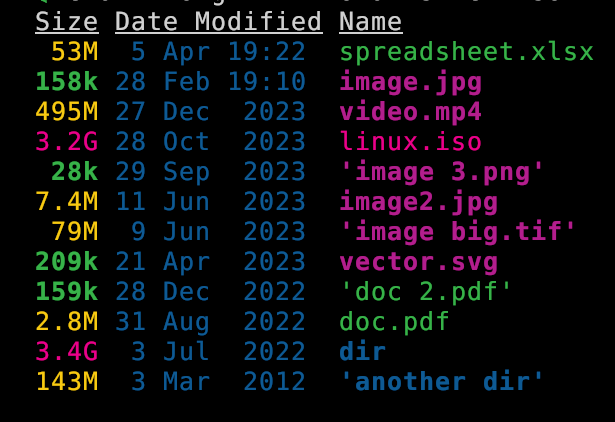 Of course it take a little while to load large directories so you will not want to use by default. Looks like it was first implemented Oct 2023 with some fixes since then. ([Changelog](https://github.com/eza-community/eza/blob/main/CHANGELOG.md)). [PR #533 - feat: added recursive directory parser with \`--total-size\` flag by Xemptuous](https://github.com/eza-community/eza/pull/533)
**Question:** Is there any auto-correct that works globally in all (or at least, many) applications? Particularly non-terminal. So for example firefox (like this text box I'm typing into), chat, text editors, word processors etc? **Example:** I often type "teh" when I meant "the". I would like to have that change automagically. I'm sure somewhere in my life (not in linux --- maybe on mac?) I had the ability to right click on a red-underlined misspelled word in any application and select "always change this fix this to.." and then it would. **Autokey** is the only close suggestion I can find. But I guess you have to tell it about every single replacement through the configuration? Are there any pre-made configurations of common misspellings? How is the performance if you end up with dozens, hundreds, of phrases for it to look out for? **Not looking for:** a code linter, command line corrections or grammerly which are the suggestions I have found when searching.
I have a multiple user linux system. Well actually a couple of them. They are running different distros which are arch-based, debian-based and fedora-based. I want to globally use non-executable components not available via my system's package manager. Such as themes, icons, cursors, wallpapers and sounds. Some of them are my own original work that I manage in git repos. Others are downloaded as packages/collections. If there is a git repo available I prefer to clone because it can theoretically be updated by pulling. And sometimes I make my own forks or branches of other people's work. So it's really a mix. I want to keep these in a totally separate area where no package manager will go. So that it is portable and can be backed up / copied between systems without confusion. Which is why I don't want to use `/usr/local`. I also want to be able to add/edit in this area without `su` to `root`. So that I can easily modify or add items which then can be accessed by all users. Also a reason to avoid `/usr/local` I tried making a directory like `/home/shared/themes` then symlinking `~/.themes` in different users to that. It sometimes worked OK but I ran into permissions issues. Git really didn't seem to like sharing repos between users. I can live with only using a single user to *edit* the repos but it didn't like having permissions recursively changed to even allow access. Is there a way to tell linux to look in a custom location for these resources for every user on the system? I also still want it to look in the normal places so I can use the package managers when possible. **fonts - once solved** On one install, I found a way to add a system-wide custom font directory though I am not able to recall how that was done. I believe it had to do with xorg or x11 config files. I can't seem to find in my shell histories how it was done but I will look some more. I do recall the method was highly specific to fonts and didn't appear to be transferable to other resources.
I am forced to use some proprietary software at work. The software lets users export custom functionalities. You can then share these to other users. I have made some that are pretty simple, but greatly enhance the use of the application using its native tooling. I'd like to share mine under some sort of open source licence rather than being ambiguous. Mostly to spread awareness of the concept of open source which is at approximately 0% right now. What are the considerations here? Can I use the GPL or is it inherently out of compliance since you need a proprietary software to run it? The employer doesn't claim any intellectual property rights over my work product. I'm not able to find anywhere that the proprietary vendor does either. But I haven't gone through everything with a fine tooth comb. What language would I be looking for? Advice appreciated. Obviously it can only be general as many details are missing. I just don't understand the details of licences very well.
I accidentally removed a xubuntu live usb from the computer while it was running but it seems to be working just fine. I can even launch applications that werent already open. Is that expected? I have always thought you need to be careful to avoid bumping the usb drive or otherwise disturbing it. Where is everything being stored? In RAM? Is the whole contents of the usb copied into RAM or just some parts? Edit: tried it with manjaro and it fell apart. All kinds of never before seen errors. Replacing the usb didnt fix it. Couldnt even shut down the machine, had to hard power off.
I've been using manjaro for a couple of years and I really like it. especially the wide variety of packages available. Recently been using [`yay`](https://github.com/Jguer/yay) to find/install. I prefer to run FLOSS packages when they are available. But I do not find a convenient way to preferentially seek these out. Even to *know* what licenses apply without individually researching each specific package. It does not seem to be possible to search, filter or sort based on license in the web interface for [`packagegs`](https://archlinux.org/packages/) or [`AUR`](https://aur.archlinux.org/packages). I do not find anything about it in [man `pacman(8)`](https://man.archlinux.org/man/pacman.8) or [man `yay(8)`](https://github.com/Jguer/yay/blob/next/doc/yay.8). The only way I have found to find license info from the terminal is using [`expac`](https://github.com/falconindy/expac). You can use `%L` to display the license. I guess you could combine this in a search to filter, similar to some of the examples listed on [pacman/Tips and tricks - ArchWiki](https://wiki.archlinux.org/title/Pacman/Tips_and_tricks). But I haven't quite got it to work. This seems like something other people would want but I don't find any available solution for it. Am I missing something? Or is it something with the arch-based distros?

I really like advance [find and replace](https://docs.kde.org/stable5/en/kate/katepart/kate-part-find-replace.html) in kate editor. You can optionally use regex and operate on multiple files. *Very* importantly it has a robust preview changes ability. it is comfortable to use even with lots of hits, lots of files. So you do not need to apply a bunch of changes and *hope* you considered every permutation as with a cli tool like `sed`. One thing that would really improve my life would be a tool like this which allows you to save search queries and options. Don't work for me: - Kate has a popup for history in the fields which is somewhat helpful but limited. When trying out different queries you don't have a way to remember which one actually *worked* so going by the history just ends in repeating the same errors over and over. Also it doesn't match the "find" and "replace" fields nor does it associate them with the other options like directory, etc. - Keeping notes in a text file is of course possible but cumbersome. I would like the computer to do work like that for me. For single file searches regex101.com (non floss) and regexr.com ([GPLv3](https://github.com/gskinner/regexr/)) are great in-browser tools for learning and you can save the search. But to operate locally on many files, it doesn't work. Does anyone know any tools that do anything like this? Can find various utilities which operate on *file names* but I am looking for *file content*. Certainly this exists ya? (Post image is screenshot from Kate website of Kate on windows.)

Anytime I search for an addon via the search box in `settings` > `add-ons manager` I get all these theme results. Here is a [search for "syntax"](https://addons.mozilla.org/en-US/firefox/search/?q=syntax) (via the `add-ons manager`) I had to make it very zoomed-out to fit long page into screen cap: 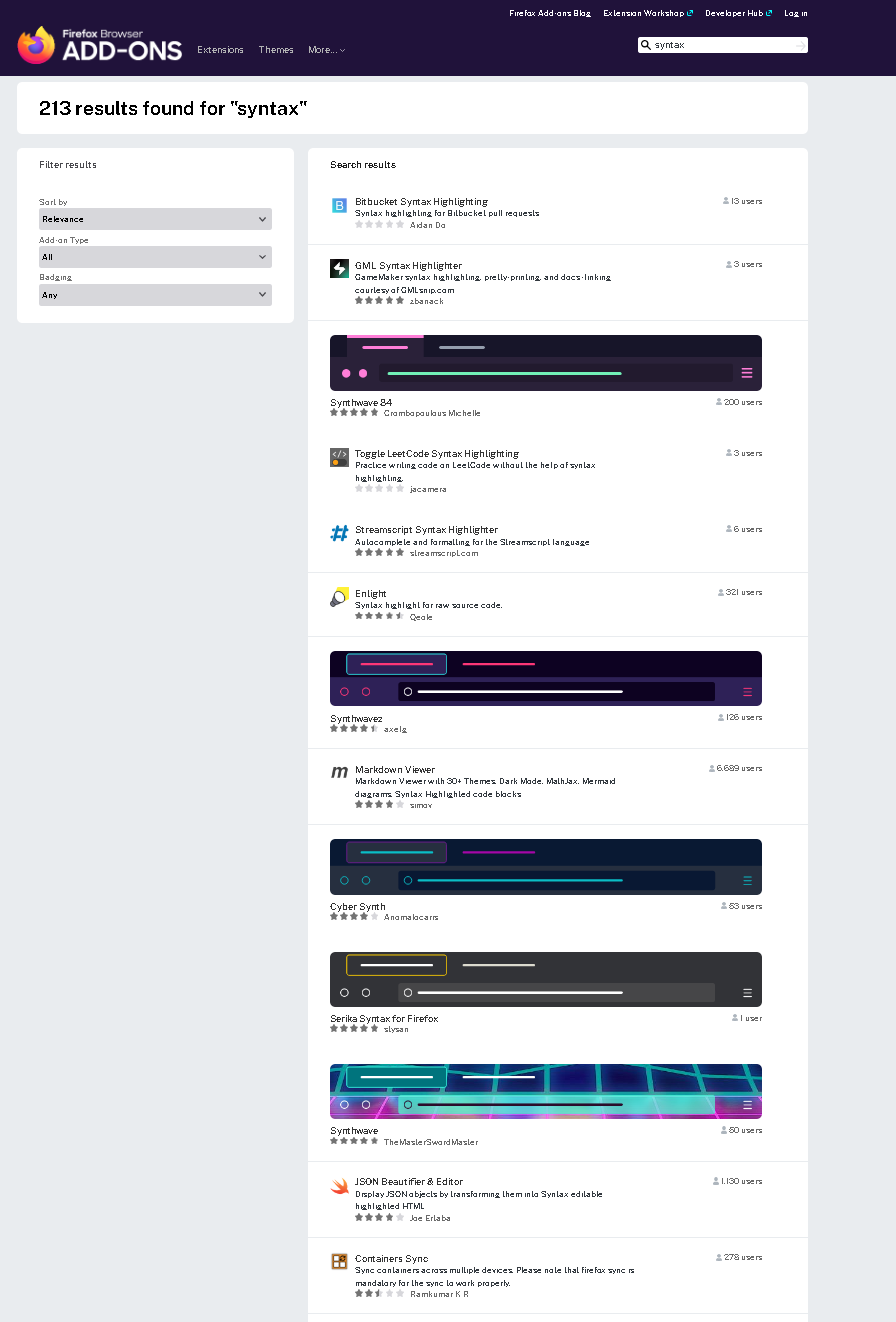 I use themes personally to visually differentiate between profiles. And I have *nothing* against fun and frivolous user customizations. Am not hating on the concept. I am curious about why they are so aggressively pushed so that they show up be default when trying to search for **add ons** you need to toggle off every time. Searching for an add-on to do something and searching for a theme that has some keyword included seem to me like totally different tasks and mixing them up is a strange choice. Is this like a major things firefox thinks people like about it? *Do* people like it?
I am learning some bash scripting. I am interested to learn about getting input for my scripts via a GUI interface. It seems that `yad` (forked from `zenity`) is the most robust tool for this. (But if there is a better choice I would like to hear about it too.) Is it possible to obtain *2 or more* named variables using `yad`? *Not* just getting the values based on their positions (`$1`, `$2`, etc), with `awk`. See "What doesn't work" spoiler for those. ::: spoiler What doesn't work I find how to obtain *one* named variable, for [example](https://askubuntu.com/questions/489497/store-the-return-string-to-a-variable-from-zenity): ```sh inputStr=$(zenity --entry --title="My Title" --text="My Text:") ``` I also find solutions relying on opening single-variable dialogues sequentially but that's a terrible interface. Everything else relies on chopping up the output with `awk` or based on the positions, `$1`, `$2`, `$3` etc. In [this script](https://askubuntu.com/a/1251429) `$jpgfile` is obtained: ```sh jpgfile=$(echo $OUTPUT | awk 'BEGIN {FS="," } { print $1 }') ``` This seems unmanageable because adding a new field or failing to provide input for a field will both change the output order of every subsequent value. It's way too fragile. ::: For a simple example, I want to ask the user for a file name and some content. Creating the dialogue is like this: ```sh yad --title "Create a file" --form --field="File name" --field="Content" ``` If you fill both fields the output in the terminal is `file|this is some text|`. How do I get them into variables like `$filename` and `$filecontent`? So then I can finish the script like this: ```sh touch "$filename" echo "$filecontent" > $filename ``` Is this possible??? I do not find it anywhere. I looked though all kinds of websites like [YAD Guide](https://yad-guide.ingk.se/), [yad man page](https://www.mankier.com/1/yad), [smokey01](https://smokey01.com/yad/). Maybe I missed something. On [yaddemo](https://github.com/cjungmann/yaddemo/) I read about bash arrays and it seemed to come close but I couldn't quite piece it together.
cross-posted from: https://discuss.tchncs.de/post/9585677 > My dream: I want a way to arbitrarily close and later open groups of applications including their states such as open files, window arrangement, scrollback, even undo histories etc. So working on a specific project I can close everything neatly and return to it later. > > In my research/experiments here is what I come up with, do you agree?: > > 1. in the terminal-only environment this would be tmux or another multiplexer > > 2. But when you start including GUI applications (which I must), then it is something else that doesn't exactly exist > > 3. Applications store their current states in a variety of places and some of them don't really *do* restoring in any way so it would be hard to force. > > 4. the best option for this is something like [xpra](https://github.com/Xpra-org/xpra/) where you can have multiple sessions. If you had a machine that stayed powered-on all the time it might be possible to create sessions, log in remotely and use them that way. > > 5. Using xpra or similar the sessions are never really actually closed. You would only close the connection from the local machine. If the machine faces a power off then too bad. As far as I can se there is basically no way to accomplish this goal where power-offs are accommodated. > > I have tried some remote-login options but they are too slow for normal use. I tend to have pretty low-end hardware running (because so far it works for most things) so maybe if I upgraded it would improve. > > 1. is it plausible? > 2. how to estimate hardware/performance needs of host, client and LAN? anything else to consider? > > I typically use manjaro + XFCE but would be willing to try something different to accomplish the goal. I only want to do this locally on LAN not remotely. > > ::: spoiler re XFCE session manager > XFCE has session management but the majority of programs don't totally work with. Like maybe the application will re-open when the session is restored but no files will be open even if they were when session was saved. Or distribution through workspaces, window size etc will not be restored. > ::: >
My dream: I want a way to arbitrarily close and later open groups of applications including their states such as open files, window arrangement, scrollback, even undo histories etc. So working on a specific project I can close everything neatly and return to it later. In my research/experiments here is what I come up with, do you agree?: 1. in the terminal-only environment this would be tmux or another multiplexer 2. But when you start including GUI applications (which I must), then it is something else that doesn't exactly exist 3. Applications store their current states in a variety of places and some of them don't really *do* restoring in any way so it would be hard to force. 4. the best option for this is something like [xpra](https://github.com/Xpra-org/xpra/) where you can have multiple sessions. If you had a machine that stayed powered-on all the time it might be possible to create sessions, log in remotely and use them that way. 5. Using xpra or similar the sessions are never really actually closed. You would only close the connection from the local machine. If the machine faces a power off then too bad. As far as I can se there is basically no way to accomplish this goal where power-offs are accommodated. I have tried some remote-login options but they are too slow for normal use. I tend to have pretty low-end hardware running (because so far it works for most things) so maybe if I upgraded it would improve. 1. is it plausible? 2. how to estimate hardware/performance needs of host, client and LAN? anything else to consider? I typically use manjaro + XFCE but would be willing to try something different to accomplish the goal. I only want to do this locally on LAN not remotely. ::: spoiler re XFCE session manager XFCE has session management but the majority of programs don't totally work with. Like maybe the application will re-open when the session is restored but no files will be open even if they were when session was saved. Or distribution through workspaces, window size etc will not be restored. :::
I am really struggling to replace facebook messenger / whatsapp for a few casual conversations. My friends and I are all wanting to move away. We are not heavy users of this but need it to work. I think the requirements are: - floss client for android, linux, windows - persistent history across devices - reasonable security - don't need to self host server - can send a message to offline user, they get it when they come online - not tied to or reliant on phone number / cell service - ETA: end user documentation explaining how to set up and common troubleshooting tried: - matrix: the thing with having to keep track of room keys and stuff is too complicated. every time someone uses a new device it is a ton of issues and we could never quite get it ironed out - signal: tied to phone number, no history across devices - xmpp: similar to matrix the key situation is confusing, also no cross device history - ETA: simpleX: a lot of people here are mentioning simpleX. It didn't come up in previous investigations so will give it a shot. - ETA 2: It doesn't seem to have persistent history across devices. Clarification? I actually didn't think this would be such a problem but it is breaking us. we don't need a lot of sophisticated features like voice, video, moderation, 1000s of participants, spam protection etc that seem to be of concern to the projects. just simple text chat.
I really like comparison tables on wikipedia but find them hard to navigate. For example: [Comparison of web browsers > General Information](https://en.wikipedia.org/wiki/Comparison_of_web_browsers#General_information) Say I want a web browser for Linux which has been recently updated. I can sort by the "Platform" column, or by "Latest release: Date" but not both. Sometimes tables can be very wide and/or very tall. Once you get to scrolling it is impossible to see either the row or column headings. So then you can't tell where you even are in the table. Example: [Table of AMD processors](https://en.wikipedia.org/wiki/Table_of_AMD_processors) Also they can have complex structures with merged headings and content. Ideally I would like to apply some basic spreadsheet-type operations like hiding rows/columns, filtering, sorting by multiple columns etc. Even if there was a way to easily get the table into an actual spreadsheet that would be helpful. I tried some extensions that export tables to other formats but nothing worked without a lot of cleanup. Is there some kind of trick or tool or extension that makes these ginormous tables useful? I can't tell how people even add information to these things, they are so large.
I really like comparison tables on wikipedia but find them hard to navigate. For example: [Comparison of web browsers > General Information](https://en.wikipedia.org/wiki/Comparison_of_web_browsers#General_information) Say I want a web browser for Linux which has been recently updated. I can sort by the "Platform" column, or by "Latest release: Date" but not both. Sometimes tables can be very wide and/or very tall. Once you get to scrolling it is impossible to see either the row or column headings. So then you can't tell where you even are in the table. Example: [Table of AMD processors](https://en.wikipedia.org/wiki/Table_of_AMD_processors) Also they can have complex structures with merged headings and content. Ideally I would like to apply some basic spreadsheet-type operations like hiding rows/columns, filtering, sorting by multiple columns etc. Even if there was a way to easily get the table into an actual spreadsheet that would be helpful. I tried some extensions that export tables to other formats but nothing worked without a lot of cleanup. Is there some kind of trick or tool or extension that makes these ginormous tables useful? I can't tell how people even add information to these things, they are so large.