

General_Effort 1w ago • 60%
Huh. What a weird coincidence. Out of all the many communities in Canada, it just happens to be the indigenous ones that have to make do without clean water because of military spending. What are the odds?
General_Effort 2w ago • 100%
How did I not know that until now?
Unironically, I'd like to know. Not having a go at you. There seem to be lots of people who don't know that. But without that bit of knowledge, the holocaust doesn't make sense.
The nazis defined anyone with jewish grandparents to be part of a jewish race, by law. That even included a few christian priests. Of course, the nazis didn't invent the idea. People never liked converts much. When you prosecute someone, you want to get the loot. It's never about selflessly helping people go to heaven.
Historically, it's a truism that a race is a result of racism. First, a group is hated or subjugated. Then membership - and supposed negative traits - become defined as unalterable, heritable facts.
General_Effort 2w ago • 100%
It sounded kinda like: Let's make people sell the properties they rent out so that wealthy people can buy vacation homes.
The idea is guaranteed to make homelessness worse, so it seems natural that someone might mock it.
General_Effort 2w ago • 40%
I can't tell if you're joking.
General_Effort 2w ago • 100%
After a quick skim, seems like the article has lots of errors. Molmo is trained on top of Qwen. The smallest ones are trained on something by the same company as Molmo.
General_Effort 2w ago • 100%
The fighter pilots ramming bombers were expected to bail out. There were survivors.
The pilots of the Leonidas squadron were expected to "self-sacrifice" in their attacks on bridges. They faced rather less social pressure than Japanese pilots, though.
General_Effort 2w ago • 100%
There were a small number of kamikaze attacks against Oder bridges in conventional planes. https://en.wikipedia.org/wiki/Leonidas_Squadron#Oder_bridge_attack_missions,_April_1945
There also was a squadron of conventional fighters dedicated to fly ramming attacks against bombers, which was used. https://en.wikipedia.org/wiki/Sonderkommando_Elbe
Eventually, these tactics are not that crazy. In war, lives and machines are expended to reach a goal. If some tactics seem crazy, then only because that fundamental fact is harder to ignore.
General_Effort 2w ago • 100%
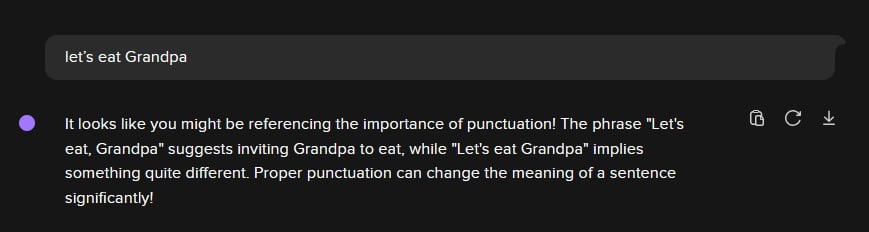
via https://duckduckgo.com/?q=DuckDuckGo+AI+Chat&ia=chat&duckai=1 with GPT-4o mini
General_Effort 2w ago • 100%
Does anyone know why nfts are so small?
Because storage space on "The Blockchain" is very expensive.
The blockchain is a complete list of all transaction made with a cryptocurrency. You have heard of miners. What they do is collect transactions and append them to the blockchain. Every miner must have a complete copy of the whole chain. So whenever a new NFT is created, lots of copies have to be stored and kept forever. It's just not a good solution from an engineering standpoint. But for the popular currencies, that's the smaller problem.
Every miner wants a fee for their services. That fee depends on the value of the cryptocurrency. There is no relation to the actual storage cost.
Besides, crypto does not offer any kind of DRM. If it did, the copyright industry would be all over it. Anyone can download anything on the blockchain.
The reason you can't resell games is, because the publishers don't allow it. For example, Steam has a marketplace. It would be no technical problem to make games transferrable between users. The rights-owners don't want that.
General_Effort 2w ago • 100%
Ich hab das wohl nicht gut erklärt. Es geht bei solchen Prozentzahlen darum, ob die Unterschiede zwischen den Menschen durch geerbte genetische Unterschiede oder durch etwas anderes (Umwelteinflüsse) verursacht werden. Dazu betrachtet man die Abweichungen von einem Durchschnitt und versucht diese Abweichungen statistisch der Umwelt oder den Genen zuzuschreiben. In meinem konstruierten Beispiel ist implizit, dass schwarze Haare der Durchschnitt sind. Blondes Haar ist die Abweichung, die entweder den Genen oder der Umwelt prozentual zugewiesen wird.
Wenn alle Menschen in etwas gleich sind, dann gibt es keine Unterschiede, die man Umwelt oder Genen zuschreiben könnte. ZB wo alle Menschen schwarzhaarig sind, dann kann das im Einzelfall geerbt sein oder weil die Person sich mit Färben angepasst hat. Das kann man aber nicht mehr rausfinden, indem man die Abweichungen in der Haarfarbe betrachtet.
In der Praxis läuft das natürlich um einiges anders. Aber das mathematisch korrekt zu erklären, ist ziemlich aufwendig.
General_Effort 2w ago • 100%
The FTC under Biden has begun to push back against tech monopolies.
General_Effort 2w ago • 66%
Maybe you could call it recoupment but it doesn't have quite the same ring. It's not quite the same thing, either.
You could also talk about coercive monopolies but that doesn't mean exactly the same thing.
General_Effort 2w ago • 100%
Ich habe noch nie einen solchen Beitrag gesehen, in dem vernünftig erklärt wird, was diese Prozentzahlen bedeuten. Also hol ich das mal nach.
Übrigens haben solche Zwillingsstudien auch Einschränkungen. Man kann nicht zwischen Genetik und frühesten Einflüssen im Mutterleib und nach der Geburt unterscheiden. ZB ein Hang zu bestimmten Nahrungsmitteln könnte auch plausibel durch Prägungen in dieser Zeit erklärt werden. Bestimmte Medikamente (zB Contergan/Thalidomid) oder Alkohol können großen Einfluss haben. Wenn eine Mutter ihre Zwillinge zur Adoption gibt, dann sind das eher tragische Fälle, bei denen psychische Krankheiten (und damit Psychopharmaka) oder Drogensucht wohl häufiger sind als im Durchschnitt.
Aber was die Prozentzahlen angeht... Man stelle sich eine Schulklasse im Süden vor, in der alle schwarzhaarig sind. Jetzt geht einer hin und blondiert sich die Haare. Der Einfluss der Umwelt auf die Haarfarbe ist 100%. Die Umwelt erklärt die Varianz der Haarfarbe in der Klasse vollständig. Die Unterschiede bei der Haarfarbe haben keine genetische Ursache.
Wenn jetzt ein Zuwanderer aus dem Norden, mit blonden Haaren, in die Klasse kommt, dann sind 50% der Unterschiede genetisch. Wenn der Rest der Klasse dann blond super-cool findet und sich mehr Leute die Haare blondieren, dann sinkt der genetische Einfluss wieder. Wenn man sich eine hiesige Klasse vorstellt, dann gibt es alles zwischen hellblond und schwarzhaarig. Wenn sich da einer blondiert, dann ist der Anteil der Unterschiede, der durch die Umwelt erklärt wird, entsprechend geringer, weil die Varianz durch Genetik höher ist.
Jetzt überlegen wir, wie das bei der Intelligenz aussieht. Wenn jeder optimale Bedingungen vorfindet, dann ist der Einfluss der Gene 100%, denn die Gene sind dann das einzige, was limitieren kann. Optimale Bedingungen heißt nicht nur Förderung und Zugang zu Bildung, sondern auch gute Ernährung und Gesundheitsvorsorge, damit die Gehirnentwicklung nicht physisch limitiert wird.
Optimale Förderungen heißt nicht, dass alle gleich behandelt werden. ZB, wenn jemand genetisch bedingt ADHS hat, dann wird das beim IQ-Test und beim Bildungserfolg limitieren. Um das Limit aufzuheben, braucht es individuelle Behandlung. Wenn jeder die gleichen Umweltbedingungen vorfindet, dann ist der Einfluss der Genetik definitionsgemäß 100%, aber das ist nicht optimal.
Man stellt auch tatsächlich fest, dass die Intelligenz in reichen Ländern eher genetisch bedingt und in armen Ländern eher umweltbedingt ist. In ärmeren Ländern ist es eben eher Glückssache, ob jemand hinreichende Bedingungen vorfindet, um das genetische Potenzial auszuschöpfen. Eine hohe soziale Ungleichheit bedingt einen geringen Einfluss der Gene und umgekehrt.

 www.faz.net
www.faz.net
>Die Zivilrichter in Hamburg ließen sich jedoch nicht von dem Argument des Fotografen überzeugen. Kneschke habe keine Beweise für eine gewisse Einflussnahme eines kommerziellen KI-Unternehmens auf LAION vorgelegt, hieß es in ihrer Urteilsbegründung. Damit sei es ihm nicht gelungen, einen Gegenbeweis zur Erlaubnis nach Paragraph 60d UrhG vorzulegen. Damit musste sich das Gericht nicht mehr mit der weiteren Schranke im Urhebergesetz beschäftigen. > >Dennoch teilte die Kamme ihre Auffassung mit: ob und unter welchen Voraussetzungen ein solcher Vorbehalt als „maschinenlesbar“ bewertet werden kann, sei von der technischen Entwicklung zum jeweiligen Nutzungszeitpunkt zu beurteilen. Das Gericht sah einen Wertungswiderspruch darin, den Anbietern von KI-Modellen einerseits über die Schranke des Text und Data-Mining die Entwicklung immer leistungsfähigerer Modelle zu ermöglichen, ihnen aber andererseits zur Prüfung etwaiger Vorbehalte nicht auch die Anwendung schon bestehender KI-Modelle abzuverlangen. > >[...] >Aufgrund der großen Bedeutung des Falls für die gesamte Kreativbranche ist eine Berufung zum Hanseatischen Oberlandesgericht sehr wahrscheinlich.
General_Effort 3w ago • 100%
If the same user can generate the same input, it will result in the same hash.
Yes, if. I don't know if you can guarantee that. It's all fun and games as long as you're doing English. In other languages, you get characters that can be encoded in more than 1 way. User at home has a localized keyboard with a dedicated key for such a character. User travels across the border and has a different language keyboard and uses a different way to create the character. Euro problems.
https://en.wikipedia.org/wiki/Unicode_equivalence
Byte length of the character is irrelevant as long as you’re not doing something ridiculous like intentionally parsing your input in binary and blithely assuming that every character must be 8 bits in length.
There is always some son-of-a-bitch who doesn’t get the word.
- John F. Kennedy
General_Effort 4w ago • 100%
You should accept Unicode; if doing so, you must count each code as one char.
Hmm. I wonder about this one. Different ways to encode the same character. Different ways to calculate the length. No obvious max byte size.
General_Effort 4w ago • 100%
I think, for a lot of people, technology has come to mean a few websites, or companies.
There are a few lemmy communities dedicated to AI, but they are very inactive. Basically, I'd have to send you to Reddit.
General_Effort 4w ago • 78%
Americans may be seeing serious savings in that picture.
I am seeing serious evolutionary pressure on liver genetics.
General_Effort 4w ago • 100%
Das wird so nicht funktionieren. Es ist ziemlich egal, wie du die Verleumdung verbreitest. Es kommt darauf an, dass du es tust.
In diesem Fall ist es ziemlich unwahrscheinlich, dass irgendjemand bei OpenAI jemals auch nur von diesem Mann gehört hat. Wie können sie ihn dann verleumden?
Sollte sein Ruf durch das Produkt gelitten haben, dann gäbe es wahrscheinlich die Möglichkeit Schadenersatz zu verlangen. Der Artikel gibt aber keinen Hinweis auf so einen Schaden. Ich sehe nicht mal einen Hinweis, dass sonst irgendwer ChatGPT über den Mann befragt hätte, geschweige denn die Aussage geglaubt hat.
 annas-archive.org
annas-archive.org
>We can only expect these trends to continue to worsen, and many works to be lost well before they enter the public domain. > >We are on the eve of a revolution in preservation, but “the lost cannot be recovered.” We have a critical window of about 5-10 years during which it’s still fairly expensive to operate a shadow library and create many mirrors around the world, and during which access has not been completely shut down yet. > >If we can bridge this window, then we’ll indeed have preserved humanity’s knowledge and culture in perpetuity. We should not let this time go to waste. We should not let this critical window close on us. > >Let’s go. > >- Anna and the team
This was published in November 2023, but may be of general interest now, because of current events.



 blog.wikimedia.de
blog.wikimedia.de
>Was hier am Ende des Rechtsstreits entschieden wird, wird auch Auswirkungen auf die Arbeit von Wikimedia haben, gerade was unsere Arbeit in der Softwareabteilung mit Open-Source-Communitys betrifft.
Is it even for real?




>The key problem is that copyright infringement by a private individual is regarded by the court as something so serious that it negates the right to privacy. It’s a sign of the twisted values that copyright has succeeded on imposing on many legal systems. It equates the mere copying of a digital file with serious crimes that merit a prison sentence, an evident absurdity. >This is a good example of how copyright’s continuing obsession with ownership and control of digital material is warping the entire legal system in the EU. What was supposed to be simply a fair way of rewarding creators has resulted in a monstrous system of routine government surveillance carried out on hundreds of millions of innocent people just in case they copy a digital file.
cross-posted from: https://lemmy.world/post/16327419 > cross-posted from: https://lemmy.world/post/16324188 > > > The Mozilla Builders Accelerator funds and supports impactful projects that are vital to the open source AI ecosystem. Selected projects will receive up to $100,000 in funding and engage in a focused 12-week program. > > > > Applications are now open! > > > > June 3rd, 2024: Applications Open > > July 8th, 2024: Early Application Deadline > > August 1st, 2024: Final Application Deadline > > September 12th, 2024: Accelerator Kick Off > > December 5th, 2024: Demo Day
 future.mozilla.org
future.mozilla.org
cross-posted from: https://lemmy.world/post/16324188 > The Mozilla Builders Accelerator funds and supports impactful projects that are vital to the open source AI ecosystem. Selected projects will receive up to $100,000 in funding and engage in a focused 12-week program. > > Applications are now open! > > June 3rd, 2024: Applications Open > July 8th, 2024: Early Application Deadline > August 1st, 2024: Final Application Deadline > September 12th, 2024: Accelerator Kick Off > December 5th, 2024: Demo Day
future.mozilla.org
The Mozilla Builders Accelerator funds and supports impactful projects that are vital to the open source AI ecosystem. Selected projects will receive up to $100,000 in funding and engage in a focused 12-week program. Applications are now open! June 3rd, 2024: Applications Open July 8th, 2024: Early Application Deadline August 1st, 2024: Final Application Deadline September 12th, 2024: Accelerator Kick Off December 5th, 2024: Demo Day
 www.iais.fraunhofer.de
www.iais.fraunhofer.de
The contingent approved via a EuroHPC “Extreme Scale Access” comprises 8.8 million GPU hours on H100 chips and has been available since May. With the new computing capacities, small models in the range of 7 to 34 billion parameters and large models with up to 180 billion parameters can be trained from scratch. The new EuroLingua models are based on a training dataset consisting of 45 European languages, dialects and codes, including the 24 official European languages. This gives a significant weight to European languages and values – multilingual large language models are still rare. Training will start at the end of May 2024 and the first joint models are expected to be published in the coming months. Project leader Dr. Nicolas Flores-Herr, team leader Conversational AI at Fraunhofer IAIS says: “The goal of our collaboration with AI Sweden is to train a family of large language models from scratch that will be published open source.”