SkySyrup 10mo ago • 95%
Young something has been in my eye for the past twelve hours and I want to scream
SkySyrup 10mo ago • 100%
but it yummy
also expensive as fuck wtf the last time I had it it was like 12 bucks never again
SkySyrup 10mo ago • 100%
greedy music labels strike again!
SkySyrup 10mo ago • 100%
I choose to press. What did she do wrong?

let’s see how low effort posts can be rule CAPTION: A comment count totalling 196 circled in red
SkySyrup 10mo ago • 100%
my dumbass read
Cook yourself


SkySyrup 10mo ago • 100%
This looks exactly like an image that would accompany an SCP article lol
SkySyrup 10mo ago • 100%
Sure! You’ll probably want to look at train-text-from-scratch in the llama.cpp project, it runs on pure CPU. The (admittedly little docs) should help, otherwise ChatGPT is a good help if you show it the code. NanoGPT is fine too.
For dataset, maybe you could train on French Wikipedia, or scrape from a French story site or fan fiction or whatever. Wikipedia is probably easiest, since they provide downloadable offline versions that are only a couple gigs.
SkySyrup 10mo ago • 50%
A simple way would be to load the comments themselves, and then check for blocked users. But this would basically ddos the instance servers and would be extremely janky lol
or I’m being me and missing something obvious :/
SkySyrup 10mo ago • 100%
Thank you so much! Have a good break!
SkySyrup 11mo ago • 100%
tech support?? that’s going a bit far I think
ok but if everyone would accept me when coming out I think it would be worth it..
SkySyrup 11mo ago • 95%
kid called EU anticompetitive laws:

SkySyrup 11mo ago • 90%
The technology of compression a diffusion model would have to achieve to realistically (not too lossily) store “the training data” would be more valuable than the entirety of the machine learning field right now.
They do not “compress” images.



Content: creepy mark zuckerberg staring at camera with caption: This person tried to unlock your phone

The models after pruning can be used as is. Other methods require computationally expensive retraining or a weight update process. Paper: https://arxiv.org/abs/2306.11695 Code: https://github.com/locuslab/wanda Excerpts: The argument concerning the need for retraining and weight update does not fully capture the challenges of pruning LLMs. In this work, we address this challenge by introducing a straightforward and effective approach, termed Wanda (Pruning by Weights and activations). This technique successfully prunes LLMs to high degrees of sparsity without any need for modifying the remaining weights. Given a pretrained LLM, we compute our pruning metric from the initial to the final layers of the network. After pruning a preceding layer, the subsequent layer receives updated input activations, based on which its pruning metric will be computed. The sparse LLM after pruning is ready to use without further training or weight adjustment. We evaluate Wanda on the LLaMA model family, a series of Transformer language models at various parameter levels, often referred to as LLaMA-7B/13B/30B/65B. Without any weight update, Wanda outperforms the established pruning approach of magnitude pruning by a large margin. Our method also performs on par with or in most cases better than the prior reconstruction-based method SparseGPT. Note that as the model gets larger in size, the accuracy drop compared to the original dense model keeps getting smaller. For task-wise performance, we observe that there are certain tasks where our approach Wanda gives consistently better results across all LLaMA models, i.e. HellaSwag, ARC-c and OpenbookQA. We explore using parameter efficient fine-tuning (PEFT) techniques to recover performance of pruned LLM models. We use a popular PEFT method LoRA, which has been widely adopted for task specific fine-tuning of LLMs. However, here we are interested in recovering the performance loss of LLMs during pruning, thus we perform a more general “fine-tuning” where the pruned networks are trained with an autoregressive objective on C4 dataset. We enforce a limited computational budget (1 GPU and 5 hours). We find that we are able to restore performance of pruned LLaMA-7B (unstructured 50% sparsity) with a non-trivial amount, reducing zero-shot WikiText perplexity from 7.26 to 6.87. The additional parameters introduced by LoRA is only 0.06%, leaving the total sparsity level still at around 50% level. NOTE: This text was largely copied from u/llamaShill 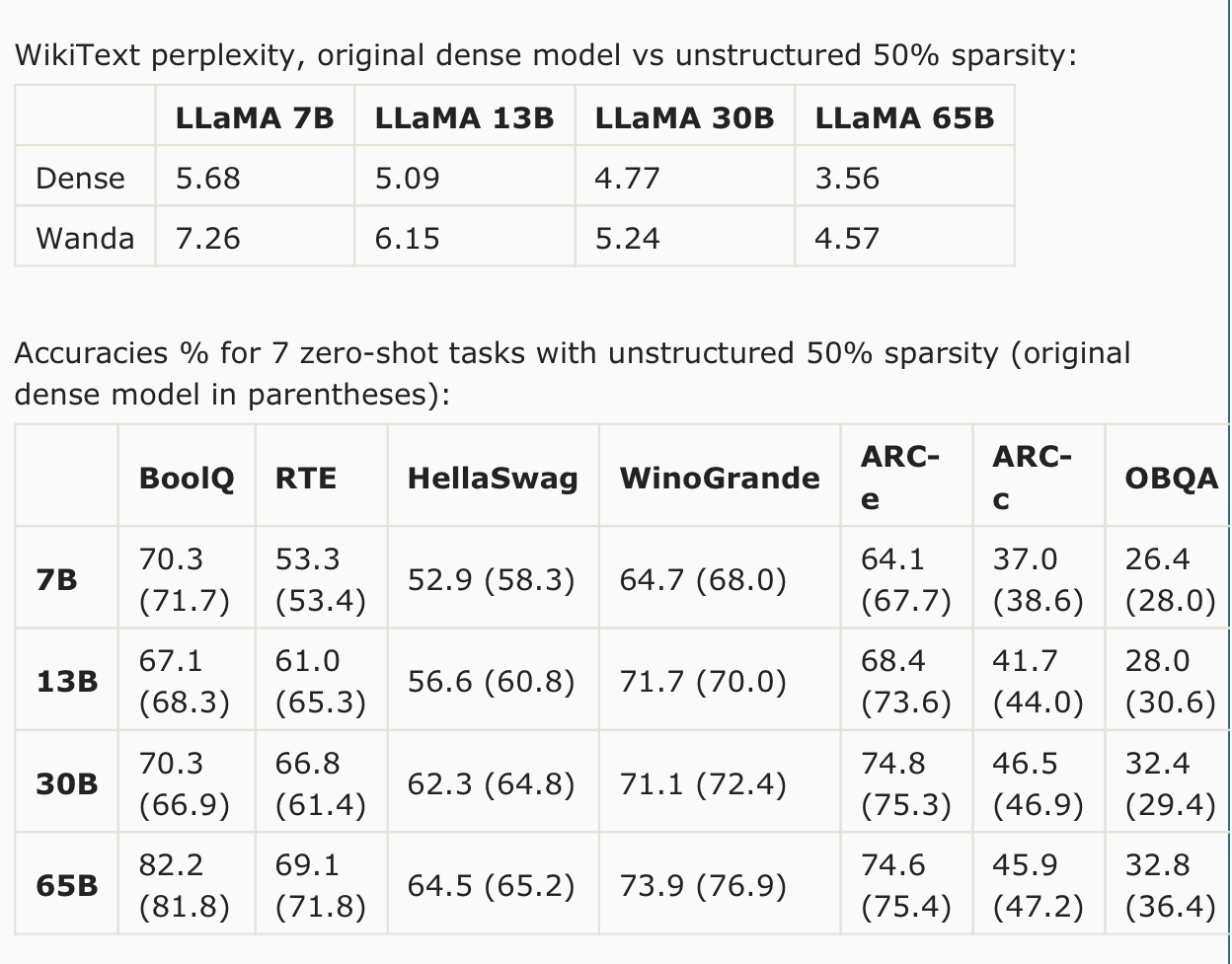

He's 15 years old now, and his ears really bother him, but he *still* brutally murders birds in our garden. the fur on the sofa is from the other cats lol
This Community is new, but I plan to expand it and partially mirror posts from r/LocalLLaMA on Reddit.
Hi, you've found this ~~subreddit~~ ***Community***, welcome! This Community is intended to be a replacement for r/LocalLLaMA, because I think that we need to move beyond centralized Reddit in general (although obviously also the API thing). I will moderate this Community for now, but if you want to help, you are very welcome, just contact me! I will mirror or rewrite posts from r/LocalLLama for this Community for now, but maybe we could eventually all move to this Community (or *any* Community on Lemmy, seriously, I don't care about being mod or "owning" it).